Back to Blog
Research
=nil; zkLLVM Circuit Compiler
Proving computations in mainstream languages with no zkVM's needed
02 Feb 2023
Introduction
Writing circuits is hard. Writing efficient circuits is even harder. If you have ever tried to do it from scratch - it’s a nightmare. Recently we went all the way of writing circuits while building zkBridges between Mina and Ethereum, and Solana and Ethereum. We’ve tried different approaches and came to the idea of zkLLVM as a key to making the process as simple and efficient as possible.
One of the main problems when writing circuits is that it requires either a deep knowledge of how a particular proof system works, either it requires an understanding of a custom domain-specific language, which limits the reusability of a code once implemented with it - custom DSLs (aka Cairo, Noir, Circom, etc.) require to give birth to the whole ecosystem of libraries and applications. Moreover, domain-specific languages are often built on top of zkVMs, which is a primary reason for performance issues.
Whenever zkVM of any kind is involved - there could be no proper efficiency achieved.
But what if we did not need to give birth to a whole new ecosystem to implement some circuit? What if we could prove mainstream languages with no efficiency trade-offs?
zkLLVM
zkLLVM is an LLVM-based circuit compiler capable of proving whatever mainstream development languages LLVM supports: C++, Rust, JavaScript/TypeScript, and other languages.
The key point is that it is a circuit compiler, not a VM. Taking high-level code as input, it transforms it into a circuit, which is then used to prove computations.
A circuit is just another form of a program
Before we proceed with the explanation, let’s remember what a circuit consists of. Every PLONK circuit basically has two parts:
- constraint system, which is a set of gates representing the algorithm and its constraints on the data.
- execution trace, a set of internal variables assignments, represents the dataset the algorithm is working with.
And zkLLVM directly transforms the code into a different representation
Since the constraint system is the same for all the data samples, while the execution trace changes from sample to sample, - we can precompute the constraint system and then use it to prove computations on different data samples.
That’s exactly what zkLLVM does. Instead of executing the code like it’s made by traditional zk Virtual Machine-based projects, our compiler compiles it into the form of a circuit, which is then used to prove computations on different data samples.
It’s fast, it’s cheap, and it’s efficient. Just transform the code into a circuit and give it to the proof producer. No custom Virtual Machine is needed anymore.
Let’s take a closer look at how it works.
Compiler pipeline produces 10x smaller circuits than zkVMs
Previously it required developers to learn a new development language and obtain a deep knowledge of the specificities of code and/or domain-specific language for target protocol computations (state proof, data aggregation, analytics etc.) and bear the endless maintenance costs with every update on the target Virtual Machine.
Here is the example of the old pipeline (TL;DR If you were forced to use a VM to prove your code - you are fucked):
-
First, you need to write the code in a custom language, which is supported by the target zkVM’s preprocessor or DSL-compiler. It requires learning a new language with its features and then transforming your algorithm on RUST or C++ into a very detailed form in the target language. It’s a very time-consuming process, often requiring completely rewritten code from scratch. Moreover, it’s not always possible to write the code in a target language because it’s not always expressive enough to represent the algorithm you want to prove.
-
After you’ve rewritten the algorithm in DSL, you need to compile the code into a target zkVM bytecode using a custom DSL compiler. It will take some time because the DSL compiler is not always swift enough - it takes your code and generates virtual machine byte code. Up to 90% of the byte code generated consist of specific service instructions for further VM processing. Even a simple code with several functions and loops generates extensive byte code.
-
Generated byte code is only the beginning. VM part - that’s where most resources are wasted. The overhead associated with using a virtual machine in the zkVM approach to circuit generation can be quite significant. One primary source of overhead is the additional computational resources required to run the virtual machine. The virtual machine must be able to execute the byte code, perform any necessary zero-knowledge proof generation and validation, and manage the overall execution environment. All of these tasks require significant computational resources, which can add to the general overhead of the system. Another source of overhead is the time needed to execute the byte code. Because the virtual machine must perform additional tasks beyond simply executing the code, the overall execution time can be longer than it would be if the code were executed directly on the underlying hardware. This can be a significant issue for systems that need to process a large number of transactions in a short amount of time.
-
The complexity of the circuits generated by zkVM can make them difficult to verify and optimise, which can further increase the overhead. Zero-knowledge proof generation and validation require many computational resources, leading to slow performance and high latency.
-
The generated circuit then needs to be proven. It requires installing a particular software, which will then take the circuit and the data sample as input and produce proof.
There are also other challenges with zkVM approach, such as scalability and performance of the system, since the zero-knowledge proof generation and validation process can be quite computationally intensive. Furthermore, it may be challenging to ensure the security and privacy of the execution in a virtual machine environment, as a custom VM is very difficult to audit and thus could potentially be compromised.
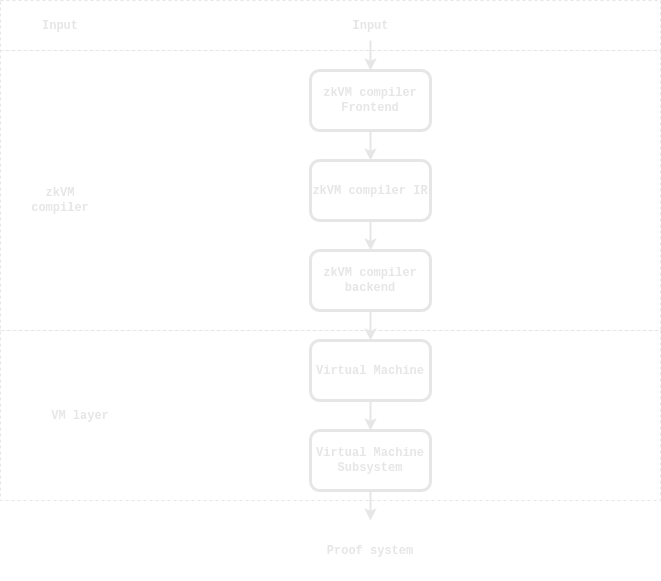
Overall, while the concept of zkVM is promising, the overhead associated with using a virtual machine can be a significant challenge that must be addressed to make it an effective solution in practice.
Build circuits with zkLLVM from mainstream languages (e.g. C++ or Rust)
Once we remove Virtual Machine from the pipeline, we can achieve much better performance and efficiency. Here is a short description of the new pipeline:
-
Write the code in a language you already know and love. It can be C++, Rust, JavaScript, TypeScript, or any other language supported by LLVM. It’s a straightforward process because you can use the code you already have. It’s not required to rewrite the code from scratch, you need to add a few annotations, and that’s it.
-
Once you’ve written the code, you need to compile it into a circuit. It takes only a few seconds - the compiler transforms the code into another form without additional instructions or overhead. It’s a very efficient process because it doesn’t require running a virtual machine or other additional services. Everything is done by a simple command line tool, which is a replacement for clang and rustc. You can use it as a part of your development environment or CI/CD pipeline.
-
The generated circuit can be used as input for the prover. But instead of installing prover on your own machine, another option is described in the section below.
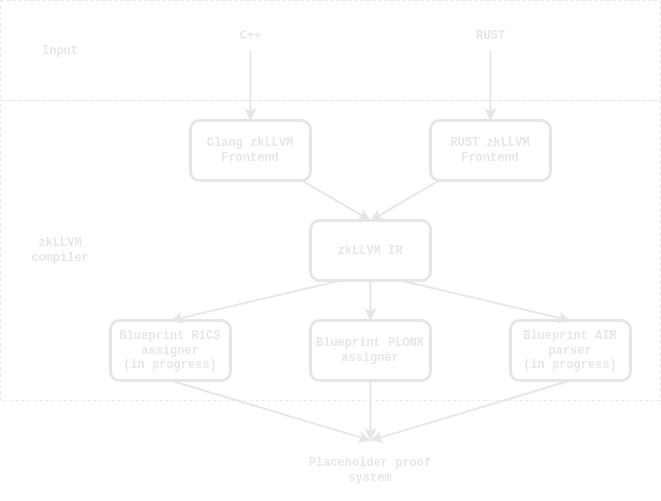
No need to set up a massive environment to produce zk proofs
zkLLVM is a standalone tool which can be used as a part of your pipeline. It’s a drop-in replacement for clang and rustc, so you can use it as a part of your pipeline. It extends your favourite compiler and language with the ability to compile your code into a circuit.
But that’s not all. You don’t even need to set up a prover to use zkLLVM. If the algorithm you want to prove is too big to run on your own machine, you always have an alternative - publish your order on the proof.market and use the computation powers of the whole community.
Once you have the proof, you can use it anywhere
The proof is a simple JSON file which can be used anywhere. You can use it in your own application or publish it on the proof.market and sell it to the community.
If you want to use a zk-proof on a decentralized platform, you obviously need to verify it somehow. We already thought about it in advance and prepared a set of verifiers you can use. It includes:
- in-EVM verifier, which can be used to verify proofs on Ethereum.
- Starknet verifier, written on Cairo language.
- Solana verifier.
- WASM-compatible verifier implementation.
And finally, you can always build a verifier from the source code and integrate it into your own application or run it locally.
zkLLVM ecosystem is backed up by powerful SDK
We wrote a lot of algorithms and data structures from scratch, so you don’t need to do it. The C++ SDK and RUST SDK (WIP) include a lot of useful stuff which can be used to build your own applications:
- Proof systems.
- Commitment schemes.
- Hashes and cyphers.
- Signatures.
- Marshalling and serialisation.
Install compiler from binaries or build it from source
- Install the toolchain:
- {Get latest binary release from the official repository:
- {…Or build it from source following the manual.
- Configure your project (with CMake in case of using C++ pipeline)
$ cmake -DCMAKE_BUILD_TYPE=Release -DCIRCUIT_ASSEMBLY_OUTPUT=TRUE ..
- Compile your circuit code like usually:
$ make circuit_examples -j$(nproc)
So, the full pipeline togethte with SDK looks like this (yes, we are also working on the SQL frontend - more about it a bit later):
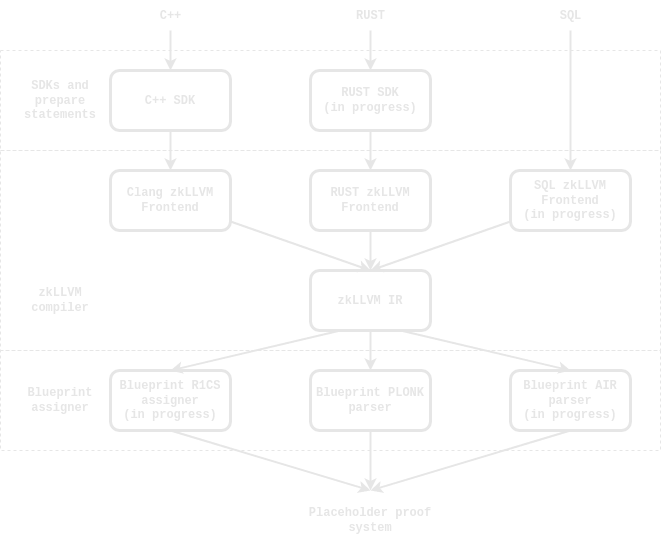
zkLLVM performs transparent code transformations
Let’s take a look at how the code is being transformed into a circuit step-by-step. At the same time, we will learn some basic stuff about writing circuits. More examples in the documentation
Every provable computations circuit begins with the entry point function, marked with [[circuit]] attribute. The function takes some arguments and returns a result. The function body represents an algorithm, which will be compiled into a circuit to further be used for proof generation.
Let’s take some simple code with arithmetic logic and walk through its compilation:
- zkLLVM compiles C++ code:
#include <nil/crypto3/algebra/curves/pallas.hpp>
using namespace nil::crypto3::algebra::curves;
[[circuit]] typename pallas::base_field_type::value_type hello_world_example(
typename pallas::base_field_type::value_type a,
typename pallas::base_field_type::value_type b) {
typename pallas::base_field_type::value_type c = (a + b)*a + b*(a-b)*(a+b);
return c;
}
- This C++ will be transformed into the following Intermediate circuit representation:
define dso_local __zkllvm_field_pallas_base @_Z19hello_world_exampleu26__zkllvm_field_pallas_baseu26__zkllvm_field_pallas_base(__zkllvm_field_pallas_base %0, __zkllvm_field_pallas_base %1) local_unnamed_addr #5 {
%3 = add __zkllvm_field_pallas_base %0, %1
%4 = mul __zkllvm_field_pallas_base %3, %0
%5 = sub __zkllvm_field_pallas_base %0, %1
%6 = mul __zkllvm_field_pallas_base %1, %5
%7 = add __zkllvm_field_pallas_base %0, %1
%8 = mul __zkllvm_field_pallas_base %6, %7
%9 = add __zkllvm_field_pallas_base %4, %8
ret __zkllvm_field_pallas_base %9
}
- Which later will be transformed into the following PLONK constraints:
constraint0: (W0 + W1 - W3 = 0)
constraint1: (W3 * W0 - W4 = 0)
constraint3: (W0 - W1 - W5 = 0)
constraint4: (W1 * W5 - W6 = 0)
constraint5: (W0 + W1 - W7 = 0)
constraint6: (W6 * W7 - W8 = 0)
constraint7: (W4 + W8 - W9 = 0)
gate0: ({0}, constraint0, constraint1, constraint2, constraint3, constraint4, constraint5, constraint6, constraint7)
- You put it to the proof.market and get proof.
{
circuit_name: hello_world_example,
constraints_amount: 8,
gates_amount: 1,
rows_amount: 1,
publc_inputs_amount: 2,
proof: 0xfoobar
}
- You verify on Ethereum/StarkNet/Solanet/wherever you want.
$verified: true
Follow zkLLVM’s official repository and documentation for more examples.
zkVMs generate a ton of constraints even for the simplest circuit
Now, we will look through the astract zkVM transformations of the same code:
- Step 1 - we take the same C++ code:
[[circuit]] int hello_world_example( int a, int b) { int c = (a + b)*a + b*(a-b)*(a+b); return c; } - Code is transformed into the Intermediate representation. It already contains many non-native operators, absolutely not related to the circuit logic:
define dso_local i32 @_Z19hello_world_exampleii(i32 %0, i32 %1) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
%6 = load i32, i32* %3, align 4
%7 = load i32, i32* %4, align 4
%8 = add nsw i32 %6, %7
%9 = load i32, i32* %3, align 4
%10 = mul nsw i32 %8, %9
%11 = load i32, i32* %4, align 4
%12 = load i32, i32* %3, align 4
%13 = load i32, i32* %4, align 4
%14 = sub nsw i32 %12, %13
%15 = mul nsw i32 %11, %14
%16 = load i32, i32* %3, align 4
%17 = load i32, i32* %4, align 4
%18 = add nsw i32 %16, %17
%19 = mul nsw i32 %15, %18
%20 = add nsw i32 %10, %19
store i32 %20, i32* %5, align 4
%21 = load i32, i32* %5, align 4
ret i32 %21
}
- The Compiler emits bytecode for the Virtual Machine. What a surprise - it contains a lot of instructions not related to the circuit logic (we simplified the asm code a bit for better readability):
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
addl -8(%rbp), %eax
imull -4(%rbp), %eax
movl -8(%rbp), %ecx
movl -4(%rbp), %edx
subl -8(%rbp), %edx
imull %edx, %ecx
movl -4(%rbp), %edx
addl -8(%rbp), %edx
imull %edx, %ecx
addl %ecx, %eax
movl %eax, -12(%rbp)
movl -12(%rbp), %eax
popq %rbp
.cfi_def_cfa %rsp, 8
retq
-
Virtual Machine executes the bytecode and produces complicated constraints, representing all this logic (including memory management, which is EXTREMELY expensive when represented in the form of a circuit).
-
…Do you really want to prove it somewhere?
Use zkLLVM for proving complex computations (aka zkGames or zkML)
Anything that needs to be trustless can be built on zkLLVM. You have GPT models but don’t want to build a datacenter to hold thousands of graphic cards? Compile the code and give it to anyone who has. Thanks to the nature of trustless computations, they will have to run the whole algorithm - without this, it won’t be possible to reproduce the SNARK proof. You don’t want to look for a suitable executor? No problem, we did it for you, publish your order on the proof.market, and you will get the whole list of executors ready to provide you with the service and the proof of the job they’ve done.
Build a zkRollup or L2 with zkLLVM
Let’s assume you are making massive logic on Ethereum. Usually, you would go and build it through zk-rollups. But with zkLLVM you can significantly simplify your pipeline.
- Take original EVM implementation.
- Compile it into a circuit with zkLLVM.
- Put your application as input data for the circuit.
- Generate proof of that circuit on the proof.market.
With its advanced optimisation algorithms, the zkLLVM compiler ensures that your result circuit will be as compact as possible.
Build a zkBridge with zkLLVM
You heard about the state-proofs we have built, right? These two:
We have built them with zkLLVM. You can do the same. Seriously - try and build your own zkBridge, it’s not that diificult anymore.
- Just take the original implementation of the blockchain you want to build a state-proof for.
- Compile it into a circuit.
- Publish it on the proof.market.
- Verify the proof on any cluster you prefer: using in-EVM verifier, using Starknet verifier, using the one on Solana.
You will get the whole list of executors ready to provide you with the service and the proof of this consensus/state-proof. Your bridge is ready to use.
Build zkOracle with zkLLVM
Looking for cheap historical data on-chain? zkLLVM is capable of proving historical queries to Ethereum, being a guarantee for your zkOracle. In the same way as with zkBridge, you can use zkLLVM to build a zkOracle for any blockchain you want.
Thus through PLONK verification on any of supported clusters you can now access validators’ stakes or other on-chain data and computations.
How to participate
Join our community and help us to make zkLLVM better: