Back to Blog
Announcements
Danksharding for various protocols via =nil; Proof Market
Pluggable Scaling via Provable Queries
05 Nov 2022
Introduction
Monolithic protocols bottleneck sufferring in terms of transactions/sec comes from peak utilization. Why? Because of the only one reason: protocols have to maintain a consistency of a crucial index - an account-value index (yeah yeah, the one you store your precious “tokens” in). It cannot be partitioned, it cannot be fragmented, its consistency is being considered as the most and the only value within the fault-tolerant full-replica databases (e.g. Eth). And the bottleneck is not a consensus, but an absurd idea of trying to fit the whole world into a single database.
For example, gas prices on Ethereum spike to 400+ gwei during a BAYC land sale event pushing transactions as high as 3,500 USD and a usual asset transfer to 200 USD. This inability to meet demand results in higher transaction costs and wait times for users.
Many attempts to solve this issue were made starting with introducing complicated native sharding protocols taking years to implement and ending with saying something like “you don’t need high throughput, it is not a database, just deal with what you have”.
Recently, an enlightenment was finally sent from above and some people started to think that it would not be possible to fit the entire world into a single database and applications would need to partition their data into application-specific cluster deployments. This gave birth to such ideas as “danksharding”, which is suspiciously similar to what the traditional DBMS industry does.
And what is that?
Independent deployments.
What happens in a traditional databases world when you need more throughput? You:
- Put up and running a new DBMS node or cluster.
- Fragment/partition already existing data to some parts.
- Put one of those parts into a newly created node/cluster.
- Implement an external coordinator/aggregator/API.
- Enjoy the throughput.
The problem with this is that it doesn’t fit the environment you can’t trust anyone in.
What happens in a “crypto industry” when you need more throughput?
- You suffer.
- You suffer more.
- You promise everyone more throughput and go off designing and implementing that for 10 years (no shit, it is quite complicated).
- You get up and running a new database, trying to convince everyone to put their data in your database ‘cause its replication protocol is faster (eventually failing obviously ‘cause no matter how hard you try, you cannot put the whole world into a single database)(so-called L2’s do that, some other L1’s do that as well).
- You get back to suffering.
This fits the environment there is no one you can trust in, but you suffer.
Yes, I’m perfectly aware of reasons why such suffering is present. A non-trusted environment and byzantine fault-tolerance requirements bring a lot of new problems to solve.
Now what if we could merge these two approaches, but exclude suffering?
Something like this:
- Put up and running a new fault-tolerant full-replica database.
- Fragment the data (by application-specific needs most probably).
- Put those fragments into newly created cluster.
- Use =nil; Lorem Ipsum as an external trustless coordinator.
- Enjoy the throughput.
This is what is being called a…
Pluggable Scaling.
Yeah. But! Not the scaling you thought about. This post basically proposes an alternative scaling mechanism comprising =nil; DROP DATABASE * nodes and =nil; Lorem Ipsum trustless data accessibility protocol as the way to help to scale a base layer using validity proofs for state and query by running a number of clusters in parallel to load balance the transaction load.
Some folks also call this approach a danksharding. But! A current approach to that supposes for Kate commitment scheme to be used which supposes a trusted setup to exist. This has luckily already been challenged in here: https://ethresear.ch/t/arithmetic-hash-based-alternatives-to-kzg-for-proto-danksharding-eip-4844/13863.
Pluggable scaling approach is closer to transparent proof system-based so-called “danksharding”.
Let’s get down to some particular advantage numbers pluggable scaling brings using Ethereum as an example.
Concepts
The following concepts will aid us in understanding the proposed solution.
State/Query proofs: These are validity proofs generated by =nil; Lorem Ipsum protocol powered by the Proof Market and =nil; DROP DATABASE * nodes which prove the state and a response to the query. Some protocols inherently generate these (Mina, Celo, Algorand); whilst those which do not (Ethereum, Solana) are implemented on a per-protocol basis by writing protocol and I/O adapters (e.g. one for Bitcoin-family protocols, one for Ethereum-family protocols etc). Generation of the proof has a cost associated with it (hardware/electricity) whilst for most use cases, verification costs are to be expressed as transaction costs as the verifiers are deployed in smart contracts.
Placeholder proof system: Placeholder is a =nil; Foundation in-house proof system in which validity proofs are generated & verified. Once a state proof of a protocol is implemented with this proof system, this allows a protocol to perform its local consistency checks before committing/implementing associated logic.
Clustering: When users notice a slowdown in response times (or higher costs) in a DBMS, it is first identified what subset of the data is causing the spike, and based on severity, it can be moved to its own partition or database. Similarly, when we see spikes in usage of a subset of data in fault-tolerant full-replica databases (e.g. Ethereum), the proposed approach is to move this to a different partition/database (cluster).
This implies, your application data can reside in more than one database or can be wholly moved to a different database cluster to ease out the throughput.
Model
We define and compare two models and the parameters which govern them. Ethereum’s production cluster is taken as a base for calculations, this can with a change of parameters can be extrapolated to any other protocol.
- Single Cluster: This behaves as the current Ethereum production cluster.
- Multiple Clusters: We take multiple Ethereum alike clusters which run alongside a main Ethereum cluster. They are their own, application-specific deployments (e.g. Aave’s own application-specific Ethereum deployment).
The model simulates transaction flows using poisson distribution to map how many transactions enter the cluster. Adjustments include a flow rate & elasticity constant; implying if the rate is high, the amount of new transactions added to the cluster will reduce. Transaction fee & gas consumed are modeled using an exponential and log-normal distribution respectively. Further details can be found in the repo.
We observe the outputs of transaction time, cost, and price for the current Ethereum production deployment.
Single cluster
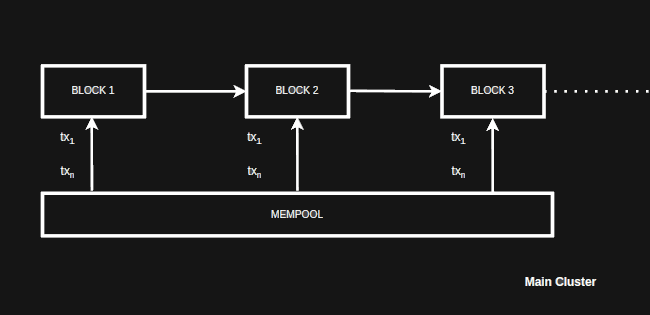
Single cluster configuration is equivalent to the current Ethereum production deployment. All transactions go to a single mempool and from there so-called “miners”/”validators” (actually just potential cluster leaders) add them to a replication packet.
Multi cluster
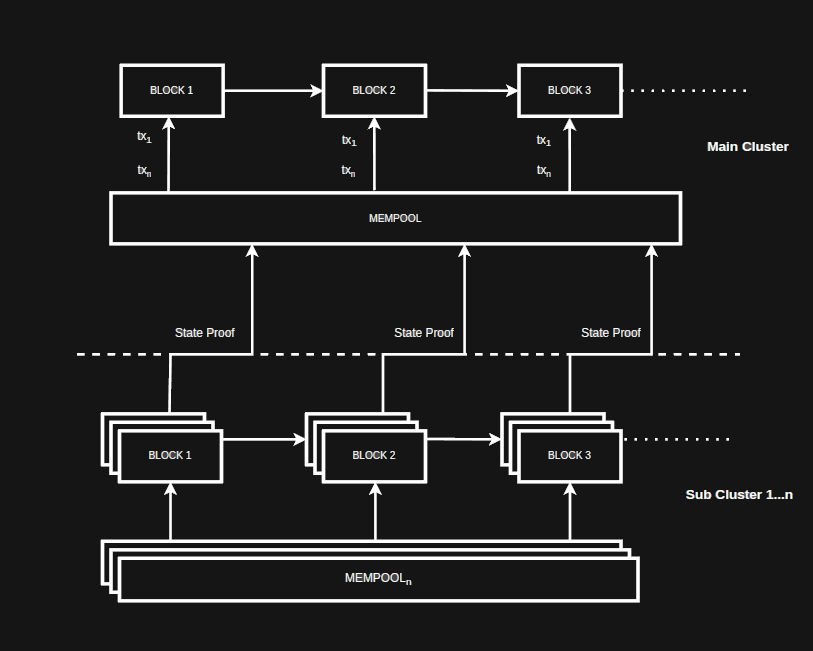
Multi-cluster configuration comprises a main cluster and one or more sub-clusters. The transaction load is split between both main and sub-clusters. Each subcluster has its own mempool. For any replication packets (or, in ape language “blocks”) created on the subcluster, a state proof is created and posted to the main cluster where it is verified on EVM.
Assumptions
The following is a subset of variables/boundaries assumed for the simulation. For the full list please see the code
Base hourly flowRate l0 := Daily Transactions/24 = ~55,000
Number of sub clusters := 10 (excluding 1 main cluster)
Main cluster load := 0.5 (50% , rest of the transactions are simulated on subclusters)
Gas consumed in average tx := 80000
CPU hours to generate proof := 8.4
Placehodler verifier gas consumption := 2,000,000
Findings
Gas Price
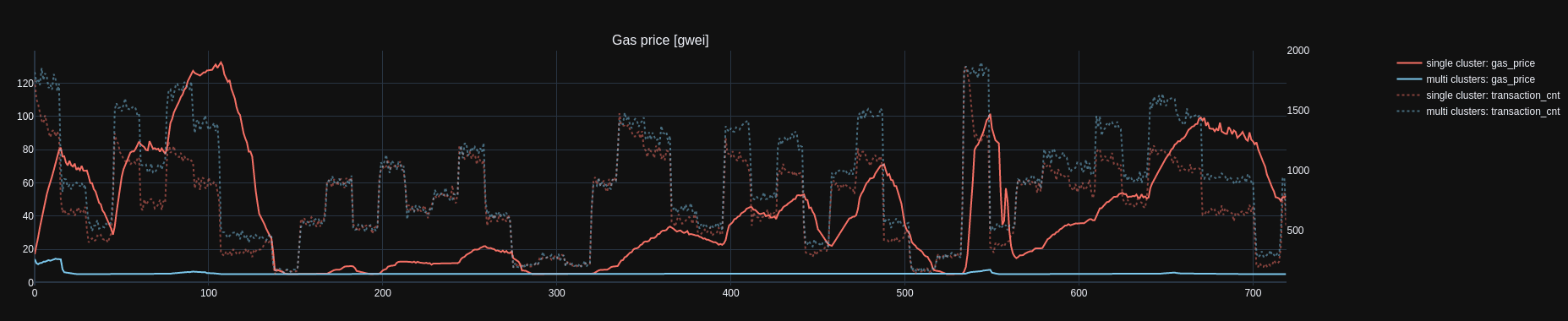 Gas price in single cluster configuration is higher and more volatile as the transaction flow registers more load. In multi cluster setup, we observe gas price is stable and low as expected as the load is shared amongst 11 clusters.
Gas price in single cluster configuration is higher and more volatile as the transaction flow registers more load. In multi cluster setup, we observe gas price is stable and low as expected as the load is shared amongst 11 clusters.
Average transaction Fees
 Average price in single cluster setup is volatile with the gas price & load. Considering a multi-cluster configuration, we notice more stable transaction costs. A fair observation is also the cost of transaction is higher when low number of transactions are being put into the protocol as this cost is associated to proof generation/verification. On average, the cost is much lower in multi cluster setup.
Average price in single cluster setup is volatile with the gas price & load. Considering a multi-cluster configuration, we notice more stable transaction costs. A fair observation is also the cost of transaction is higher when low number of transactions are being put into the protocol as this cost is associated to proof generation/verification. On average, the cost is much lower in multi cluster setup.
Average wait time
 Average waiting time for a transaction to be cleared from mempool has more spikes under loads where transactions can be waiting to be confirmed from few seconds (high gas price) to 20 minutes. Multi-cluster configuration clears the mem-pools much quicker and there is no wait lag experienced by the user.
Average waiting time for a transaction to be cleared from mempool has more spikes under loads where transactions can be waiting to be confirmed from few seconds (high gas price) to 20 minutes. Multi-cluster configuration clears the mem-pools much quicker and there is no wait lag experienced by the user.
Transactions stuck in mempool
 Any transaction which is in the mempool for over 1 hour is considered stuck for this conclusion. High variance is observed in a single cluster configuration, while multi cluster configuration shows no signs of backlog.
Any transaction which is in the mempool for over 1 hour is considered stuck for this conclusion. High variance is observed in a single cluster configuration, while multi cluster configuration shows no signs of backlog.
What did we learn?
Considering the above findings that re-envisioning so-called “networks” as clusters provides scalability benefits without having to adopt or maintain complex architectures. The security provided is on par with existing L2 solutions, with the ability to further fragment the application across different deployments all of which is secured via validity proofs.
But how is that different from “Danksharding”?
Easy question. Since =nil;-flavored “Danksharding” is powered by =nil; DROP DATABASE *, in combination with a Proof Market it does not only enables so-called “danksharding for EVM, but also enables “danksharding”-alike composability among different protocols. For example, with Solana’s state proof available on a Proof Market, it is possible for applications to enjoy Solana’s cheaper transactions, but to still use Ethereum as a settlement layer.
So, with =nil; Proof Market, regular “Danksharding” turns into state proof-based protocol composability.