Back to Blog
Research
Overcoming Security Risks in zkSharding
Exploring the security concerns in sharded systems before full ZK finalization, defining the problem of a corrupted state, and proposing a protocol to solve it.
09 Sep 2024
Introduction
zkSharding offers a promising solution for scalability issues in L2s, but it comes with its own set of security challenges, especially before settlement on L1.
One such challenge is the probabilistic security of the system:
• Randomness origins: For each epoch, a randomness beacon generates a pseudorandom seed, for example, based on users' activity. This seed is used to assign validators to shards. Assuming the seed is truly random and unbiased, as a result, the mapping is also random.
• Сonsensus safety guarantees: Validators assigned to a shard run a consensus protocol to commit proposed blocks, which provides certain safety guarantees — specifically, an invalid block could not be committed if the number of malicious validators is below a certain threshold ratio , typically a third or half.
• 1% attack: Hence, due to the randomness of the assignment, there is a non-zero probability that malicious validators could occupy a higher ratio than the safety threshold , dominating a shard, leading to the commitment of an invalid block. This type of attack is commonly referred to as a 1% attack.
Given this risk, the protocol must include mechanisms or incentives to detect such behavior and correct any resulting corrupted state. While detection is critical and expected to happen promptly (since no valid proof could be generated for an invalid state transition), our focus is on the correction aspect.
Approaches to correcting the corrupted state
Ignoring the problem (or rather "ensuring this is not a problem")
The most straightforward approach is to configure parameters so that the probability of an attack is negligibly low. Let’s break this down:
Assume that the system has validators, is a shard size, is the maximal number of malicious nodes, $f$ is a threshold security parameter of a shard, representing the maximal fraction of malicious nodes on a shard. Then, we can obtain the odds of malicious validators overtaking a particular shard, noting that a number of malicious validators occupying a shard, denoted below by , follows hypergeometric distribution:
The next step is to get the probability of malicious validators overtaking any of shards:
Let's assume for concreteness that the epoch duration is one hour; that is, validators are rotated once per hour. Meaning each hour, we flip a coin and with probability we lose, i.e., the state could be corrupted. Then, the number of epochs before the state could be corrupted follows the geometric distribution. We can roughly estimate the number of epochs before a possible state corruption as the mean of this distribution . Only roughly, since this distribution is right-skewed with a heavy tail, meaning that typical samples from this distribution might be quite far away from the mean.
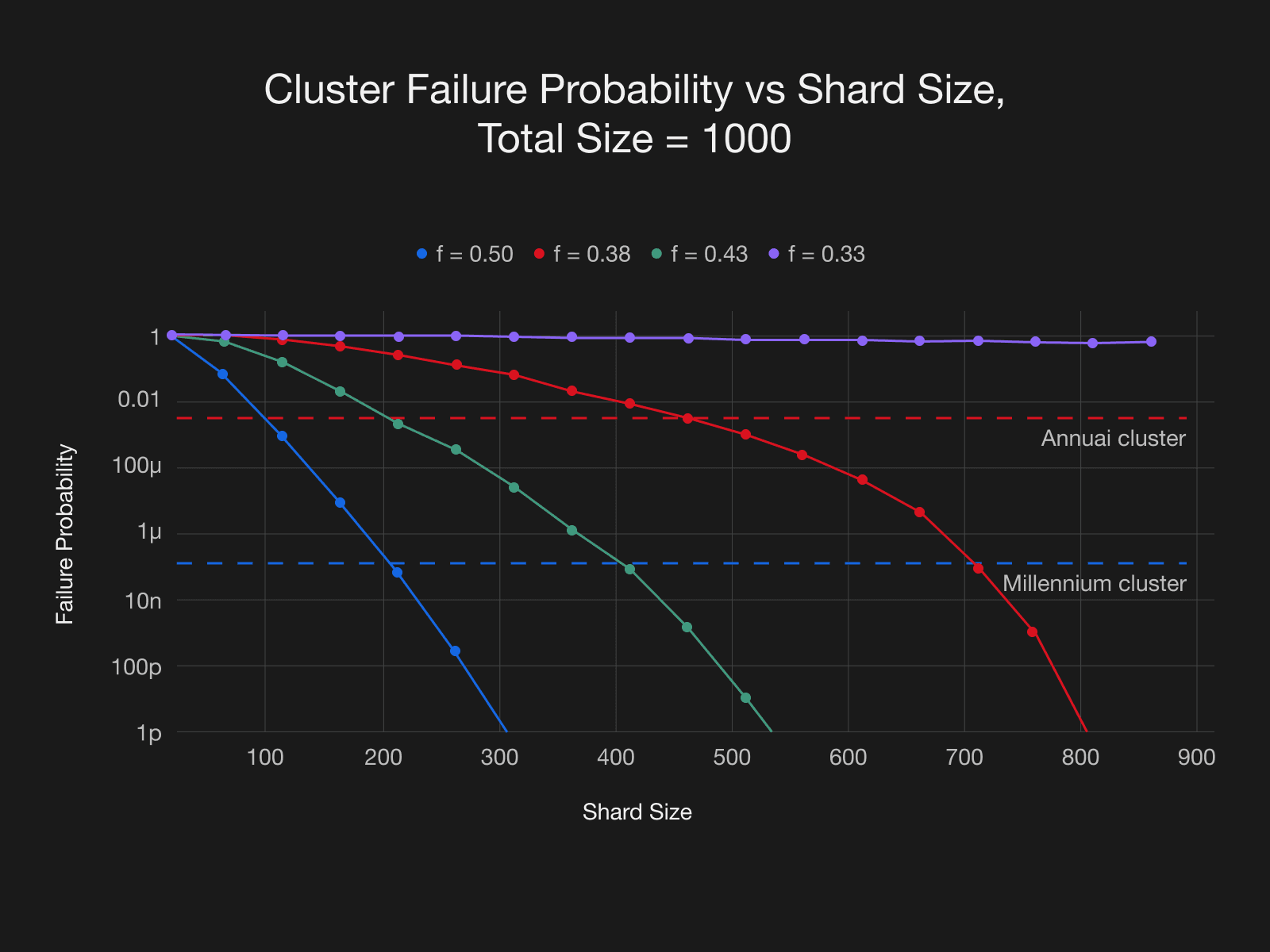
Let’s assume that we set the time until failure to a millennium, that is , and set shard’s security parameter . From the graph above we can see that achieving the desired probability requires a shard committee size of 200. That amounts only to 5 shards in total. Also, as noted above, from the properties of this distribution we can achieve a fail within 10 years with about 1% probability.
Although this approach partially mitigates risks, it significantly compromises scalability by requiring large committee sizes. As a result, it falls short as a standalone solution.
Partial Fixes
Another approach involves partial fixes, such as those proposed in TON’s initial design. This method involves tracing back from accounts that initiated a malicious state transition and identifying all accounts affected by this transition. However, this method has several drawbacks:
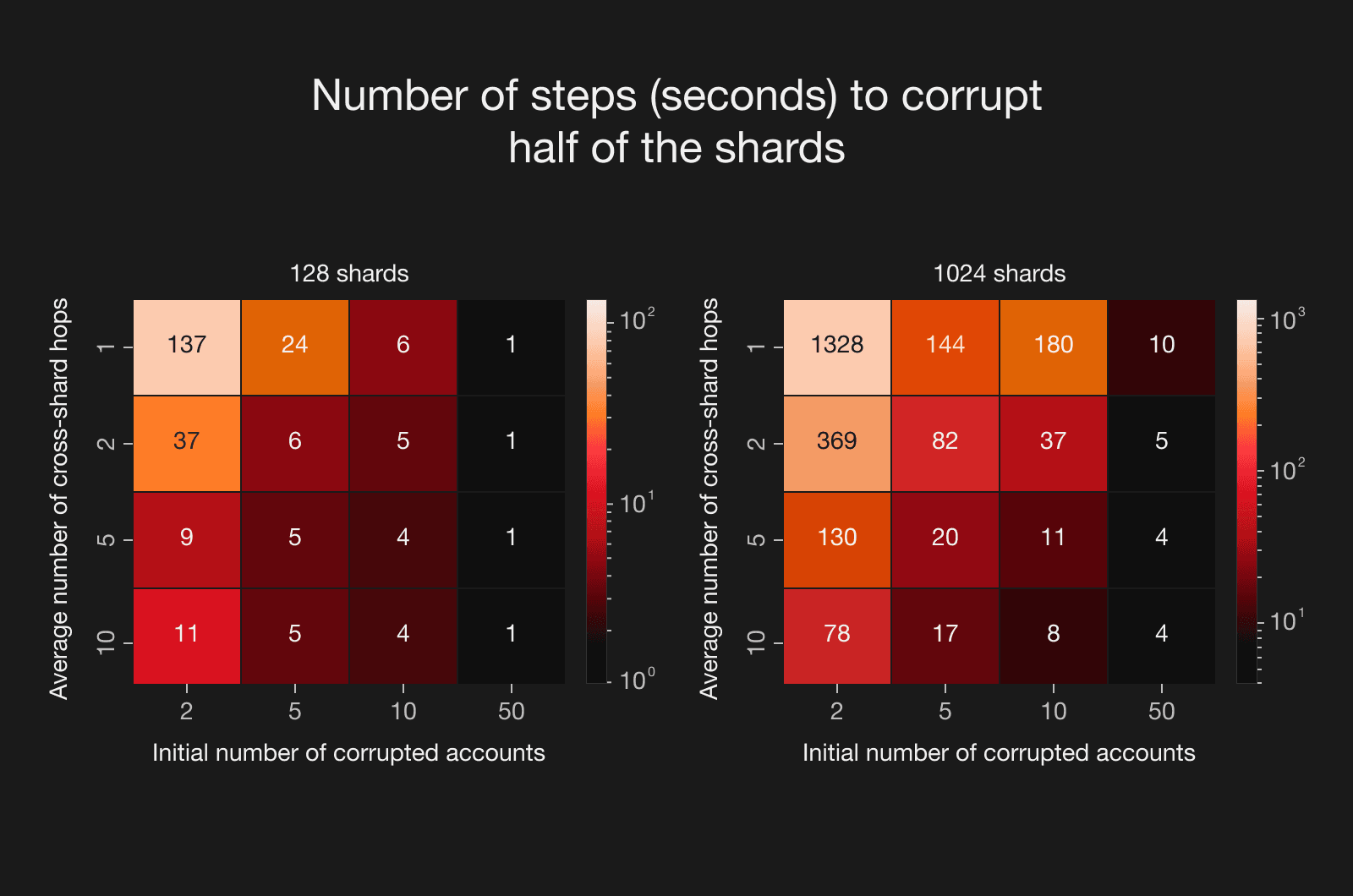
1. Proof regeneration and increased finalization latency: Since accounts that receive cross-shard transactions from a malicious account are also considered compromised; any shard containing at least one such compromised account becomes subject to state changes. The latter requires the regeneration of state transition validity proofs for the affected shards, leading to increased finalization latency. Our simulations, show that errors can propagate rapidly across shards, i.e. ratio of malicious shards to all shards increases quite fast, so the time to corrupt a half of shards is quite small:
2. Impact on User Experience: More importantly, while targeting only corrupted accounts might initially appear to be an effective strategy for enhancing user experience, we argue that the most active users are likely to still encounter the impacts of partial state updates. Much like any real-world network, the “network of accounts” has a pattern where a small subset of accounts generates the majority of activity. These high-traffic accounts (DEXes, marketplaces, gaming apps) will almost surely be subject to state corrections. Consequently, this will affect the UX of majority of users who were active at that time.
3. Fragility: Moreover, high implementation costs of partial fixes, coupled with the low probability of their trigger, , make this approach less appealing for a practical adoption.
Given these challenges, we advocate for a robust and straightforward approach: implementing a full rollback mechanism described below.
Proposal outline
Our proposed solution involves an in-protocol rollback mechanism, designed to address corrupted states effectively. Below is a visual representation of the process. Notation: "MB N" stands for the N-th main shard block, "SB i" — a block of -th execution shard.
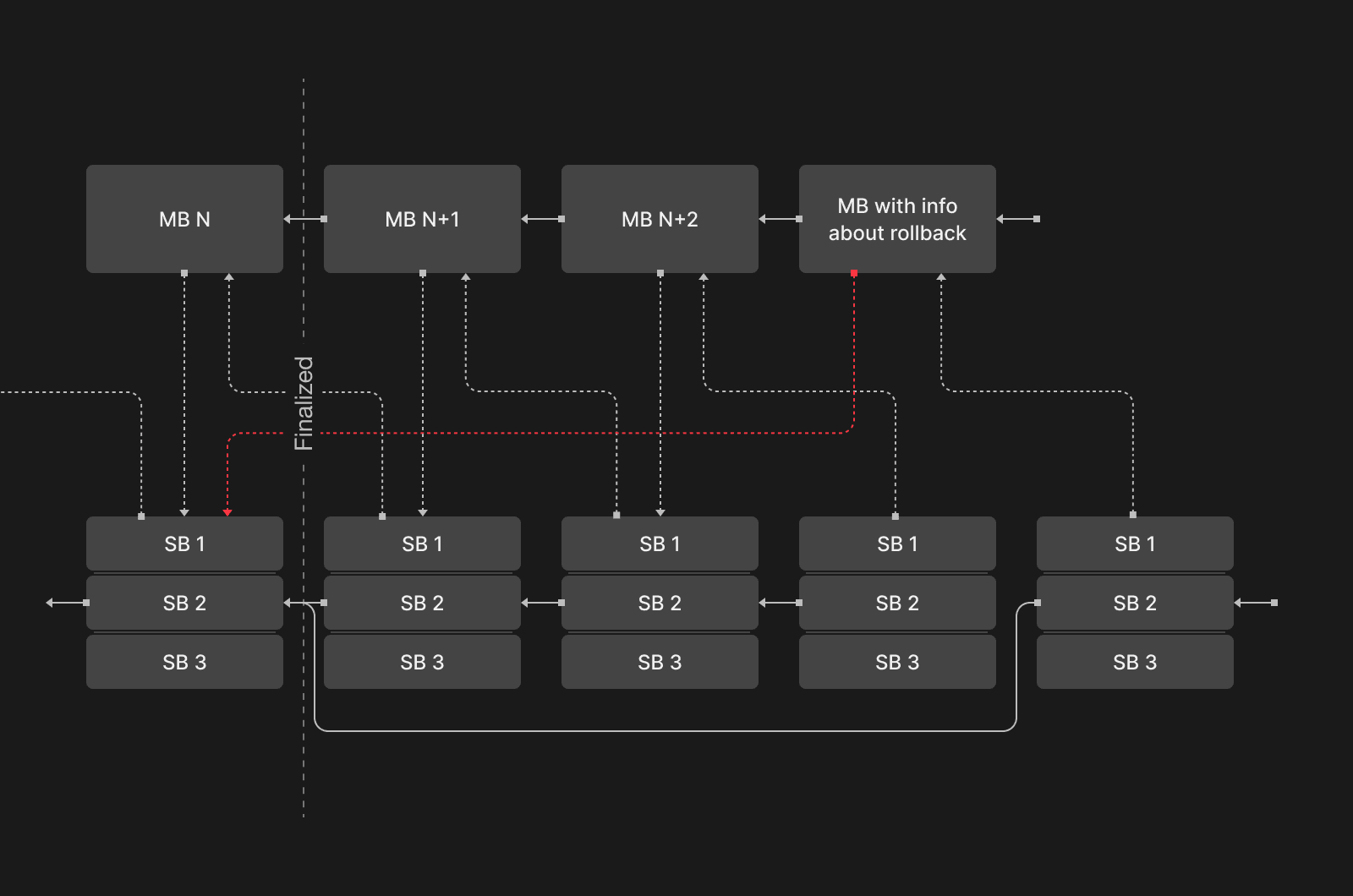
Steps:
- What we want to achieve:
- Fork from the last finalized state.
- Slash malicious validators.
- Reassign validators on the problematic shard.
- Protocol processing: Upon processing a rollback transaction in a main shard block:
1. Initiation step: Check the fraud proof of a malicious behavior
Footnote: The fraud proof submitted in the initiation step is used to demonstrate that malicious behavior occurred in the network. This proof can take the form of a zk proof or a combination of transaction data and a state witness, similar to the approach used in optimistic rollups. Because the malicious state roots are stored on-chain, each node has access to these roots and can independently revalidate the fraud proof against the known malicious state roots. This decentralized validation ensures that the proof is correct and that the rollback is justified.
2. Get the header of the last finalized main shard block, .
3. Set the main chain state root to the last finalized state root, Continue to work with this state root.
4. Set the shard blocks hashes to the hashes of shard blocks that were finalized by : .
5. Slash malicious actors — nodes who signed the fraudulent block.
6. Update consensus parameters and reassign validators if necessary.
7. Set extra info about the rollback in the block header:
Similar to Ethereum we could introduce $\texttt{extraData}$ field and in case of a rollback set it to the following string:
Benefits
- The existence of an in-protocol rollback mechanism allows for a smaller committee size, making the system more efficient and scalable. By embedding a rollback mechanism within the protocol, we disincentivize malicious parties to attempt attacks. Knowing that any corruption they cause will be automatically corrected, attackers are less likely to invest resources in such efforts. The impact of any successful attack is limited to the time scale before zk finalization, which is currently on the order of tens of minutes. As research in proof systems advances, we expect this time scale to decrease, further reducing the potential impact of malicious activities.
- The proposed solution is both simple and robust, providing a straightforward method to address corrupted states. This simplicity helps in maintaining the integrity of the system without introducing unnecessary complexity.
Final thoughts and further directions
While the proposed mechanism outlined above meets current requirements, there are several areas identified for enhancement and further exploration within the context of zkSharding, including:
- Integration of the Sync Committee, in particular managing correct L1↔L2 communication
- Compatibility with the recently proposed cross-shard communication and transaction ordering protocol, ShardDAG
We will continue to publish research on these topics in the near future. Stay up to date via our X profile or the blog.
In summary, the probability of malicious activity within our system is set to a reasonably low value, and the protocol is designed to automatically detect and fix such issues. The design of our protocol, which ensures that all shards operate under a unified framework, allows us to minimize reliance on optimistic assumptions about validator behavior.